
央国企数字化转型正式进入深水区。
近日,国资委明确表示,要加快构建“1+98+X”国资央企大数据体系,全面增强国资央企用数能力。其中,“1”是国资央企大数据平台, “98”即98户中央企业自建的数据平台,“X”是指国资委组建的国内领域的大数据平台。
实际上,构建底层大数据基础平台已成大势所趋。从数据资产管理出发,首先得从底层把数据“存”起来,再进行数据管理,最后实现数据的有效利用。
然而,现实情况是我们的数据量虽然不小,但真正有效利用的比例非常小。如何通过数据智能化平台建设,让数据成为有效数据,发挥数据价值,各个领域尤其是大型集团企业开始争相发力。
为何必须构建湖仓一体数据平台?
湖仓一体作为新一代数据智能技术,为企业的数据平台建设提供了最佳可能。
IDC数据研究预测:到2026 年,非结构化数据预计将占IDC全球数据圈中90%以上的数据。也就是说,在过去的数据量以及数据状态下,企业还能靠烟囱式架构或者技术堆栈式服务来支撑业务发展,但随着大量的视频、图片、文件等非结构化数据走向实际业务场景,其数据规模和复杂度就超越了传统的结构化数据管理范围。
为了快速响应业务需求,构建实时数据处理能力,企业必须进行平台架构的提升,解决好海量数据的高并发和实时处理要求。但问题是为什么要构建“湖仓一体平台”?答案只有一个,那就是大数据技术不断演进的结果。
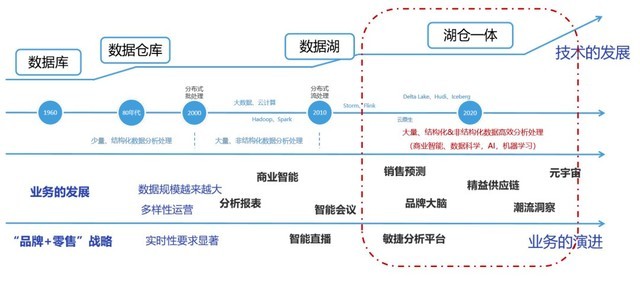
早期,企业大多建设的是以关系模型为主的数据仓库,如NewSQL具备可扩展性、且支持ACID等优势。再之后,面向在线分析处理OLAP的组织级数据资源管理成为一股新兴力量,底层的技术架构也从关系模型为主的数据仓库演化到跨模态的数据湖仓一体化平台。
1993年,E.F.Codd提出了OLAP概念,认为OLTP已不能满足终端用户对数据库查询分析的需要。1999年,Oracle发布其数据仓库产品,标志着数据仓库已经成为关系模型下OLAP的主流技术产品。2011年,谷歌 BigQuery发布后,代表数据仓库进入云时代,SQL数据库和以MapReduce并行处理模式的发展,提升了数据仓库的应用效果。2010年,美国商业数据分析工具企业Pentaho提出数据湖概念,将数据资源管理的范围,从关系型数据库中的结构化数据(行和列),扩展到半结构化数据(CSV、日志、XML、JSON)和二进制数据(图像、音频、视频)。2020年,Databricks提出Lakehouse湖仓一体概念,将数据仓库和数据湖的优势结合,进一步提升了数据质量和性能,降低了成本。
回归到央国企技术需求,从数据仓库演化到跨模态的数据湖仓一体化平台,也是必然趋势。在数据量小、数据清晰的业务模式下,企业通过数据仓库处理较小规模的精炼关系数据,且模型统一,分析能力强,更容易生成商业智能报告等;数据湖则可以处理超大规模、多模态、异构原始数据,可以低成本地统一数据存储池,支持简单的数据分析。
湖仓一体之所以更胜一筹,是因为可以融合数据仓库和数据湖优势,底层多种数据模型并存,支持异构数据的实时查询和分析,流数据分析、机器学习等。尤其当企业的实时数据处理需求增多,湖仓一体的优势逐渐突显。有数据统计,随着5G和物联网等技术的发展,全球数据规模逐渐增大,其中实时数据的比例到2025年预计将达到30%。
而且,当企业数据呈指数级增长,并行发展成第一要务,企业需要根据处理需求的不同,同时处理不同的数据,应对多种不同的并行计算模型,包括:批处理、流处理、混合处理、图处理。在实际应用场景中,往往需要同时支持多种处理模式,既有批处理,也有流处理需求,但构建两套独立的系统难协调,资源利用率低,采用Lambda架构系统复杂,难部署。而湖仓一体架构可以海纳百川,不管是小规模、低维、单源单模态的数据处理,还是海量、高维多源多模态的实时数据处理,都能在一套平台体系下搞定。
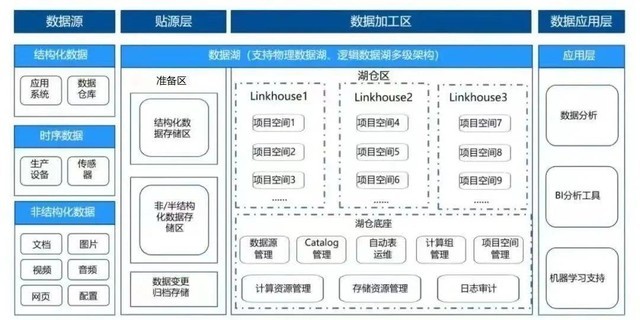
多湖多租户场景下的湖仓一体技术实践
不过,相对单一湖仓单一租户场景,大型集团企业通常分总部、子公司,业务也有多部门,要面对的最大挑战是多湖多租户场景,这带来一系列新的挑战:
第一,维护成本高。在多湖多租户场景下,系统需要支持多个湖仓实例和多个租户,这意味着需要更多的资源来维护和管理这些实例和租户。
第二,安全需求高。大型集团企业通常处理的是敏感数据,数据安全和隔离将变得尤为重要。系统需要具备更强的数据保护措施,包括数据加密、访问控制、审计等技术,以确保不同湖仓实例和租户之间的数据不会被泄露或者干扰。
第三,数据管理难度大。数据资源分布在不同的湖仓实例和租户之中,每个湖仓实例和租户都有自己独立的数据模型和元数据管理方式,以确保不同湖仓实例和租户之间的数据能够正确地进行交互和整合。
第四,需要更高的技术水平。央国企通常有更高的技术标准和安全需求,需要更高的技术水平来搭建和维护系统,这涉及到更高级的技术领域,例如分布式系统、网络安全、数据加密等。
面对这一新的场景需求,分布式数据湖技术方案提供了新的解决思路,既可管理海量的结构化和非结构化数据,同时又可以通过数据目录授权共享的方式实现跨湖查询,支持更多样化、更快速的数据分析需求。
具体来看,分布式数据湖可以支持海量数据的存储和处理,能够满足不同规模、不同类型的数据需求;具有高度灵活性,可根据具体情况进行部署和扩展,支持多语言、多框架的应用;强调数据的自描述性和元数据管理,使数据更易于理解、管理和利用。
以滴普科技实时湖仓平台FastData为例,主要提供了分布式数据湖+统一Catalog管理的思路,它可以实现多种数据源和数据湖的统一,核心能力包含:
提供物理湖(租户)/逻辑湖/项目空间的多级灵活设计,满足了复杂的业务场景
统一Catalog管理能力,连接数据孤岛,统一数据语义,提供统一权限管控能力
统一SQL引擎,满足查询加速、联邦查询和数据处理的需求
特别是基于DLink Mesh能力扩展支持多级分布式数据湖架构,连接多个数据孤岛实现多湖管理,并具备统一的多租户权限和安全管控机制,实现加速查询和联邦数据分析。在滴普科技看来,构建多级数据湖的重点,就是以物理或者逻辑的方式实现租户间的元数据隔离,同时还能保持元数据在权限控制下的分享和互通,而FastData基于物理湖(多租户)/逻辑湖/项目空间的多级灵活设计,满足多业务层级下的跨域数据湖使用需求。

湖仓一体数据技术架构带来更多可能
放眼未来,满足大型集团企业数据智能化需求的新一代大数据平台,还需覆盖几个关键能力:
1、事务支持
Lakehouse在企业级应用中,许多数据管道通常会同时读取和写入数据。通常多方同时使用SQL读取或写入数据,Lakehouse保证支持ACID事务的一致性。
2、模式实施和治理
Lakehouse应该有一种支持模式实施和演变的方法,支持DW模式规范,例如star/snowflake-schemas。该系统应该能够推理数据完整性,并且应该具有健壮的治理和审核机制。
3、BI支持
Lakehouse可以直接在源数据上使用BI工具。这样可以减少延迟,提升数据实时性,并且降低必须在数据湖和仓库中操作两个数据副本的成本。
4、存储与计算分离
事实上,这意味着存储和计算使用单独的群集,因此这些系统能够扩展到更多并发用户和更大数据量。
5、兼容性
Lakehouse使用的存储格式满足开放和标准化需求,例如Parquet,并且它提供了多种API,包括机器学习和Python/R库,因此各种工具和引擎都可以直接有效地访问数据,并且支持从非结构化数据到结构化数据的多种数据类型。
就目前来看,国内外各大厂商都已经在重兵部署“湖仓一体”技术方案,如亚马逊云科技的Redshift Spectrum、微软的Azure Data Lake、Databricks、华为云的FusionInsight、滴普科技的FastData等,并赋能各行业数据平台建设。
作为湖仓一体数据智能基础软件独角兽,滴普科技凭借新一代湖仓一体、流批一体优势,为诸多央国企提供了数据平台建设方案。以某能源集团为例,该集团是以油气业务、工程技术服务、石油工程建设、石油装备制造等为主营业务的综合性国际能源公司,该集团希望由离线数仓升级为新一代实时湖仓,实现全量油田数据入湖。基于此,滴普科技将DLink实时湖仓引擎与该集团现有平台进行集成,支持结构化、半结构化数据的实时汇聚,同时能够实现数据实时计算、联邦查询等高级特性。
通过滴普科技的湖仓一体技术赋能,为该能源集团提供了11大类全量油田数据入湖服务,并基于滴普科技DLink Mesh提升油田勘探开发数据服务的时效性,及主数据湖和分布式区域湖管理等能力,支撑八大油气数据应用智能场景,以数据驱动业务价值,让数据实现可用、好用、易用。
小 结
技术创新为央国企的智能化创新带来了更多可能性,而满足新时代需求的湖仓一体,可以在海量数据处理、多模数据入湖和存储、湖仓数据应用、数据全链路追踪等方面,有更卓越表现,真正满足企业在大数据分析过程中遇到的敏捷性和实时性等特定场景要求。
从这个角度看,湖仓一体掀起央国企数据智能化创新浪潮,不是没有可能。要想以数据驱动业务价值,让数据可用、好用、易用,“湖仓一体”自然是大数据平台的首选。未来,随着央国企数字化转型进程加快,“湖仓一体”的发展前景或将不可估量。





